



First of all, thanks to Doug Stevenson for an enlightening chat last week around Droidcon Italy. He opened my eyes on why the emails we were getting about Squanchy Firestore rules pointed at a bigger problem than we initially thought. And many thanks to Daniele Conti for fixing it! 🙌
Over the last week or so, we’ve discovered and patched a security issue leading to potential leakage of some PIIs (Personally Identifiable Information) about speakers on two Squanchy instances for Droidcon Italy 2018, and 2019. Potentially exposed data is limited to what collected on the CfP platform for Droidcon Italy, syx.it (private sessions, email and physical addresses, mobile numbers), and does not contain passwords. Only people selected as speakers for the last two years had their data copied over to Firestore and, as such, only they have been exposed. That puts it to around 100 users’ PII being potentially exposed.
At the time of patching the issue, we were not aware of any unauthorised access to this data, but due to Firestore’s lack of logs we cannot be completely confident in this. Regardless, the issue has been fully resolved early last week. We have also immediately notified the Droidcon Italy organisers last Wednesday since they needed to patch things on the 2019 instance they control, and get in touch with all people involved.
Post-mortem
First, a bit of background. Squanchy’s Firestore instance stores data with this structure:
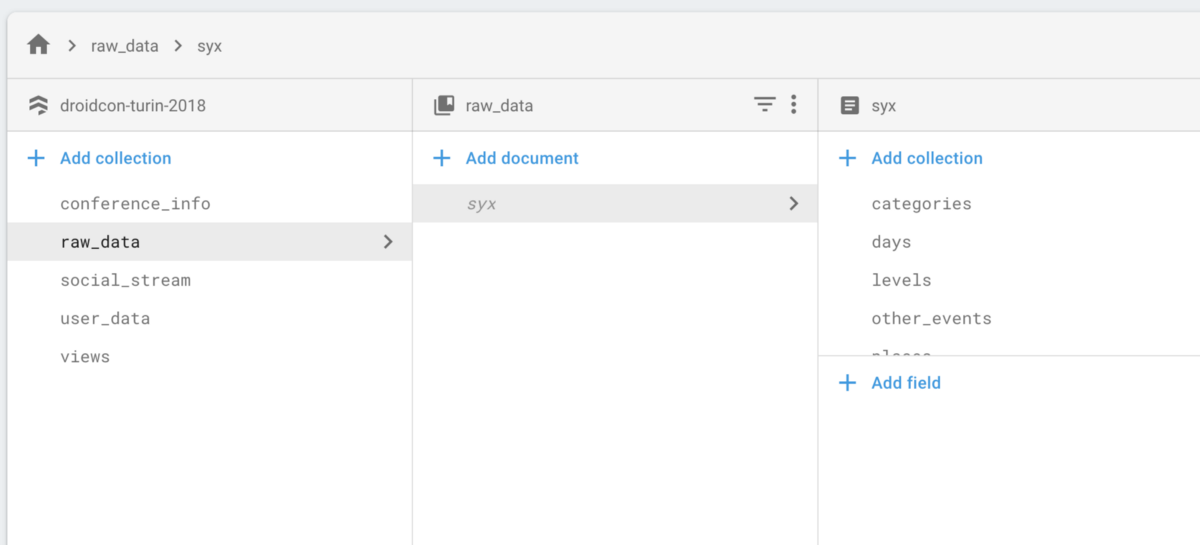
Of these, raw_data hosts all the raw info coming from the CfP (including some PIIs) and user_data contains all users’ favorited talks (but no PIIs). We wanted to disallow access to raw_data to everyone and only allow access to user_data documents matching the current user’s ID — basically, only allow a user to access their own favourites. Only our cloud functions should be able to access it to create the views, which are pre-digested data that the client can display directly.
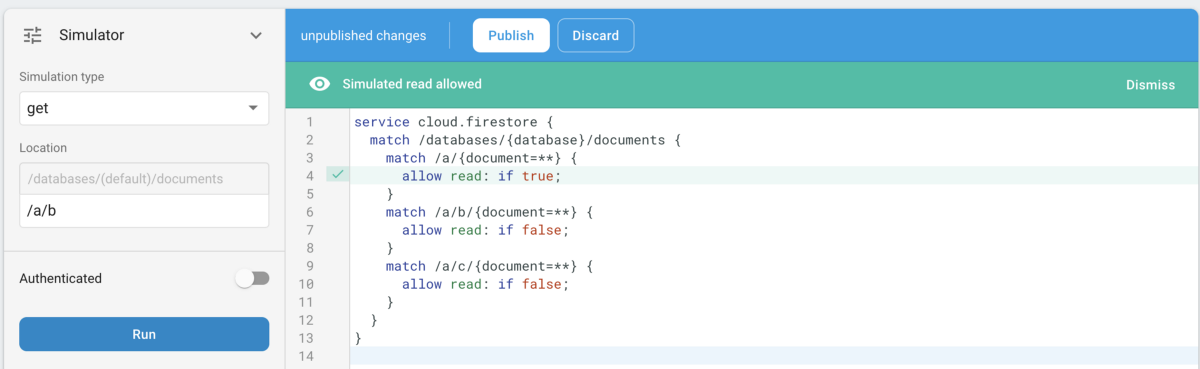
Unfortunately, we misunderstood how Firestore rules work, and back when we wrote them, there was no simulator. We followed examples and tested the positive cases and all seemed to work. Our assumption was that rules followed the commonly used pattern of “deny wins”, which means that any path disallowing access to a resource would prevail over any allowing it. For example, if you had this scenario:
a // Allow everything in here (document=**), except...
├── b // Do not allow anyone (allow read,write: if false)
├── c // Do not allow anyone (allow read,write: if false)
├── d
└── eYou would think that you can allow access to /a and then restrict access to sub-entries /a/b and /a/c, by using something like allow read: if false:
service cloud.firestore {
match /databases/{database}/documents {
match /a/{document=**} {
allow read: if true;
}
match /a/b/{document=**} {
allow read: if false;
}
match /a/c/{document=**} {
allow read: if false;
}
}
}But this is not how it actually works. Firestore rules work the other way around: if you give access to any resource you cannot revoke it with another rule — in this example, the rule allowing access to a would give access to everything inside of it, including b and c, regardless of further rules for them denying access.
Let me reiterate this:
If you give access to any resource you cannot revoke it with another rule.
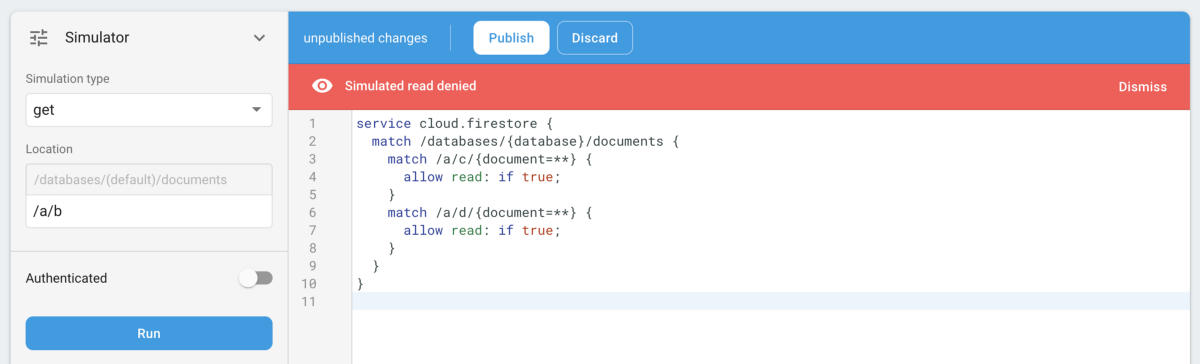
In order for things to behave as we want (allow unlimited access to /a/c and /a/d), we need to explicitly only allow access to those and not anything else:
service cloud.firestore {
match /databases/{database}/documents {
match /a/c/{document=**} {
allow read: if true;
}
match /a/d/{document=**} {
allow read: if true;
}
}
}As you can see, the trick here is to be explicit in what is allowed; if nothing specifies a given resource can be accessed, then it will not be accessible by default. This means all resources that aren’t explicitly mentioned as accessible, or writable, aren’t. The rules are about “opening up”, not “closing down” access.
What about Squanchy’s Firestore instance?
These were our default Firestore rules:
service cloud.firestore {
function userIsSignedInWith(userId) {
return request.auth.uid == userId;
}
match /databases/{database}/documents {
match /{document=**} {
allow read;
}
match /user_data/{uid}/{document=**} {
allow read, write: if userIsSignedInWith(uid)
}
}
}Squanchy uses one Firebase instance per conference, so the impact on actual users’ data may vary. Unless changed before deploying to a new instance, deployments would by defaults be affected.
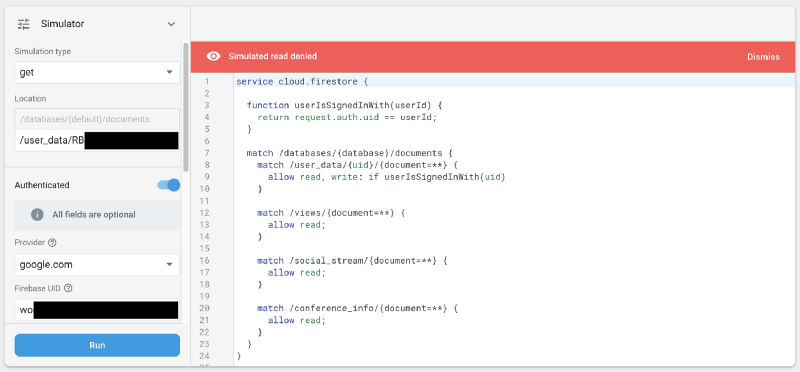
Looking at the rules with our newfound understanding of how Firestore rules work, we can immediately see there’s two problems with this. The simulator helps us confirm our suspects.
1. We’re not explicitly preventing reads to raw_data — this is quite bad, as that contains PIIs. In fact, that is a mistake we didn’t realise until we locked down the rules, and which was still a problem even with our incorrect assumptions. Nobody could still add/change/remove raw data, at least.
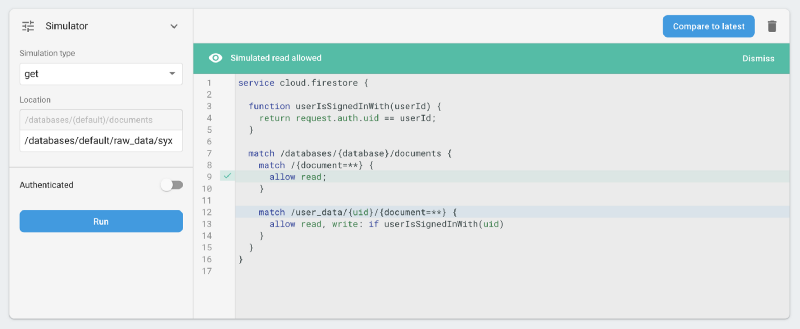
raw_data was permitted… bad!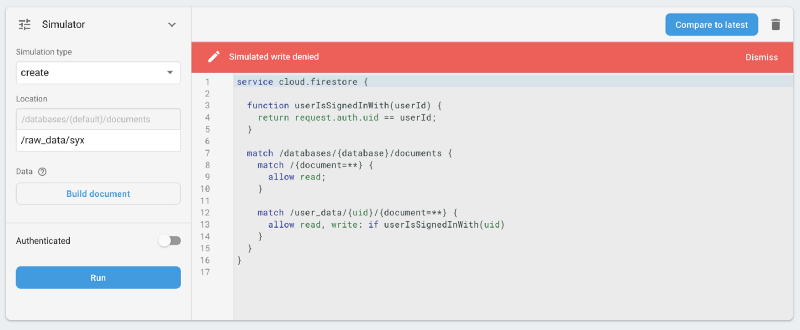
2. All users can read (but not write) all user_data contents, and thus, everyone’s favourites. Notably though, there is no straightforward way to link a UID with an actual user email address, so this data is de-facto anonymous unless someone has compromised other users’ accounts and figured their UIDs.
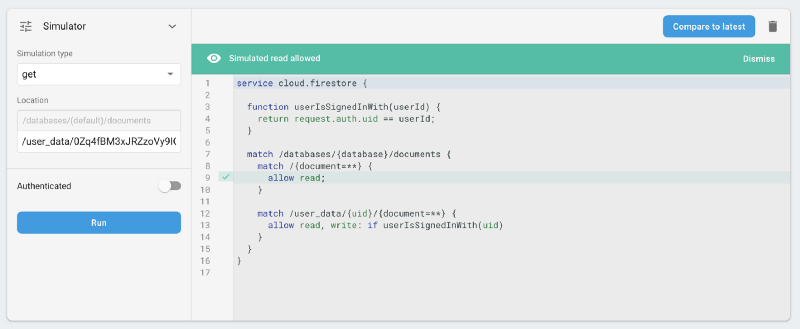
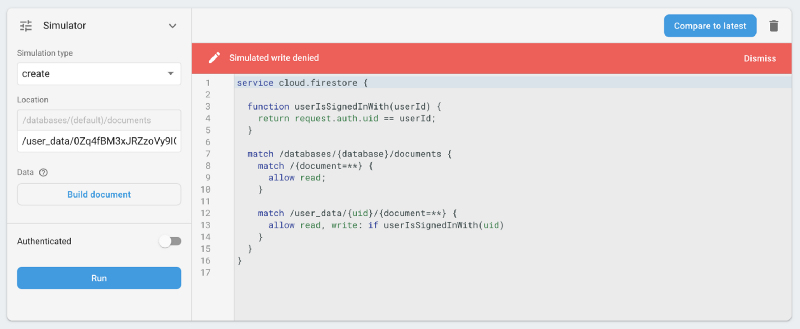
Corrective actions
Our corrective action was to patch the rules with the following:
service cloud.firestore {
function userIsSignedInWith(userId) {
return request.auth.uid == userId;
}
match /databases/{database}/documents {
match /user_data/{uid}/{document=**} {
allow read, write: if userIsSignedInWith(uid)
}
match /views/{document=**} {
allow read;
}
match /social_stream/{document=**} {
allow read;
}
match /conference_info/{document=**} {
allow read;
}
}
}Now we’re explicitly whitelisting only the parts of the Firestore DB that we want to allow users to access. Notice how raw_data is still nowhere to be found — users shouldn’t ever have access to it.
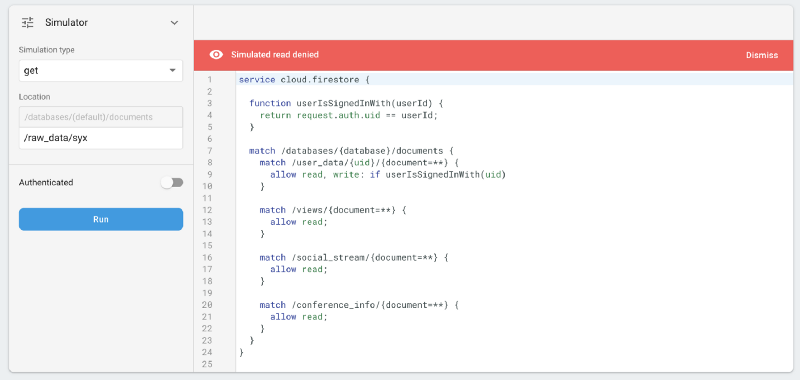
raw_data.Instead, we say: allow everyone to read the public data (the views, the social_stream and the conference_info), and only allow users to access their own “private” space under user_data/{uid}.
Since the former set of data is already publicly available on the conference website and there’s no reason to hide it, we aren’t making an effort to hide it. It’s not even behind anonymous auth, it just isn’t needed. We just want it not to be writable.
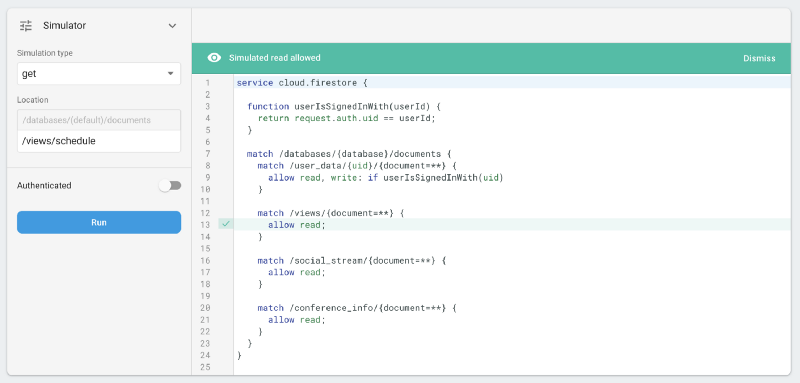
/views/schedule…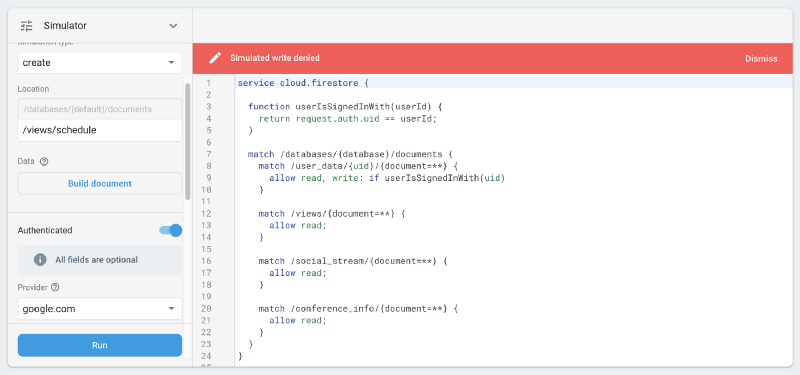
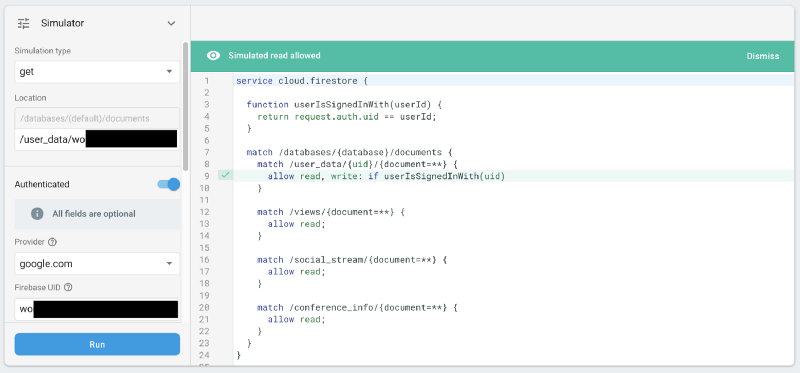
The latter data set, while not containing any PIIs or sensitive information, and being still basically anonymous due to the randomised UIDs Firebase Auth assigns to all users, is properly secured now.
Security issue impact
We’ll be honest, here — we don’t know. It’s not that we don’t want to know or don’t care; it’s simply impossible to know, since Firestore keeps zero access logs. While we doubt anyone took advantage of this while it was live (it’s since been patched out in all instances of Squanchy and forks we know were affected), there is still a remote possibility some PIIs of speakers and CfP submitters were leaked. This should only be impacting Droidcon Italy 2018 and 2019, the latter of which is not controlled by us (but has been patched by the conference organisers); other conference instances didn’t use the same raw_data structure and we had no access to any other conference’s PIIs anyway, so those aren’t affected. We’ve applied the patch to those instances as well, just in case.
Learnings
Firstly, we learnt that we had fundamentally misunderstood how Firestore access rules worked when interacting with each other. We had gotten a bunch of emails from Firestore alerting of potentially exposed data (this seems to be a common enough issue they had to put in place an automated warning for it…) but we thought it was due to some of our data being world-readable by default. We didn’t have the simulator when we wrote the rules in the first place, and when it was made available we didn’t think about testing them. Our own testing with code was also not in-depth enough to find out these issues — we simply assumed they wouldn’t need to be checked.
Takeaway: always test rules with the simulator and/or in code, covering as many edge cases as possible!
Action: ✅ We have now tested the rules with the simulator and they behave as we’d expect
Secondly, when trying to audit if any actor had accessed the unprotected data, we learnt that Firestore does not provide access logs. This is definitely something to keep in mind for unmediated access to the data storage — you have no audit trail in case of incidents.
Takeaway: Firestore should really have this feature, but we should’ve checked before adopting it.
Action: ✅ submit a feature request to the Firebase team
Lastly, we shouldn’t have held PIIs we don’t need in Firestore in the first instance. A piece of data you don’t have is a piece of data you cannot leak!
Takeaway: never store data you don’t strictly need.
Action: ✅ patch out the ability to retain PIIs in the first place from the code that handles receiving the CfP info from Syx.it
Action: ⏲ wipe out the unnecessary PIIs from the Firestore instances for Droidcon Italy 2018 and 2019 — this will be done soon, starting this weekend.
Acknowledgements
Thanks once again to Doug Stevenson for helping us understand that the Firestore emails weren’t just a false positive from some automated checks (we’ve seen quite a few from Google in the last few months… see Play Store) but we should’ve actually done something about it. Thanks to Daniele Conti who also figured out there were issues pretty much the next day, before I could tell him I had spoken to Doug, and who wrote and deployed the patch. Thanks to Mark Allison for his data regulation advice.
Thanks to all proofreaders of this post — Doug, Mark, and Daniele, Erik Hellman, and Lorenzo Quiroli.